

一、直接使用现成的工具类进行脱敏
Hutool
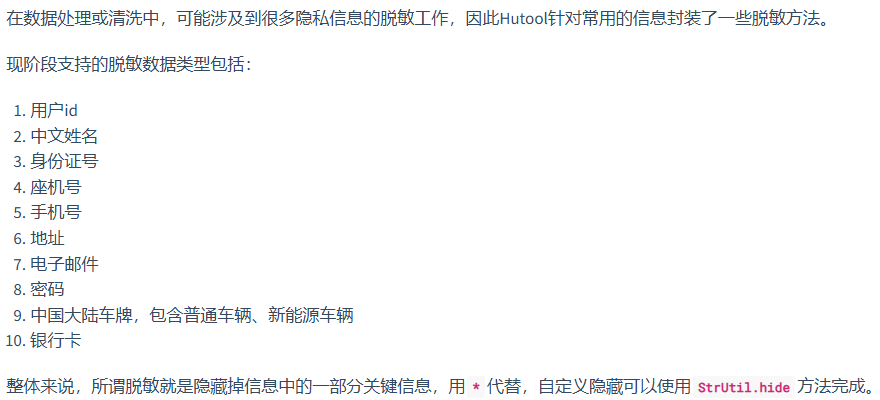
这个脱敏工具主要用于注释
需要将需要脱敏的字段传给他指定的方法中,并不能实现自动识别文本中需要脱敏的字段并进行脱敏

SensitiveBye
该工具类与Hutool类似
也不能自动识别文本中需要脱敏的字段并进行脱敏
二、使用正则表达式进行脱敏
使用一些正则表达式以及中文处理库可以实现对长文本需要脱敏的字段进行识别并脱敏
但是正确率比较感人
Java中专门为中文设计的分词工具有以下几个:
IKAnalyzer分词器:这是一个开源的,基于java语言开发的轻量级的中文分词工具包。最初是为Lucene项目设计的,后来发展成为一个独立的分词组件。
Ansj分词器:这是一个基于中科院的ictclas中文分词算法的Java实现,提供了中文分词、中文姓名识别、用户自定义词典等功能,适用于对分词效果要求较高的项目。
Stanford分词器:斯坦福大学的自然语言处理组提供的分词器,支持多种语言,包括中文。
FudanNLP分词器:由复旦大学自然语言处理研究组开发的分词器。
Jieba分词器:虽然Jieba最初是为Python设计的,但也提供了Java接口,是一个流行的中文分词工具。
Jcseg分词器:基于mmseg算法的轻量级开源中文分词器,集成了关键字提取等功能。
MMSeg4j分词器:使用Chih-Hao Tsai的MMSeg算法实现的中文分词器,并提供了Lucene和Solr的接口。
Paoding分词器:庖丁中文分词库是一个使用Java开发的,为搜索引擎分词设计的组件。
smartcn分词器:Lucene官方提供的中文分词插件,效果一般,但可以作为基础分词使用。
HanLP分词器:一个大规模的中文自然语言处理库,提供了丰富的中文处理功能,包括分词。
IKAnalyzer

只能用于进行分词
并不能用于提取人名、地址和时间等实体信息
Ansj

识别个数:29处
错误识别个数:10处
错误率:34.5%
漏脱敏/无法识别个数:3处
FudanNLP
FudanNLP目前已经停止维护,已经全部更新到FastNLP
目前只支持Python,不支持Java
Jieba
目前Java版只支持分词
不支持词性标注

HanLP

脱敏个数:20处
错误脱敏个数:7处
错误率:35%
漏脱敏/无法识别个数:3处
三、总结
综上所述
几乎所有的脱敏工具类都是传入字段进行脱敏,而不能自动识别需要脱敏的字段
实现自动识别需要自然语言分析
然后Java在自然语言识别方面不比Python更加好用,少数几个可以使用的中文处理库的正确率也不高
评论