

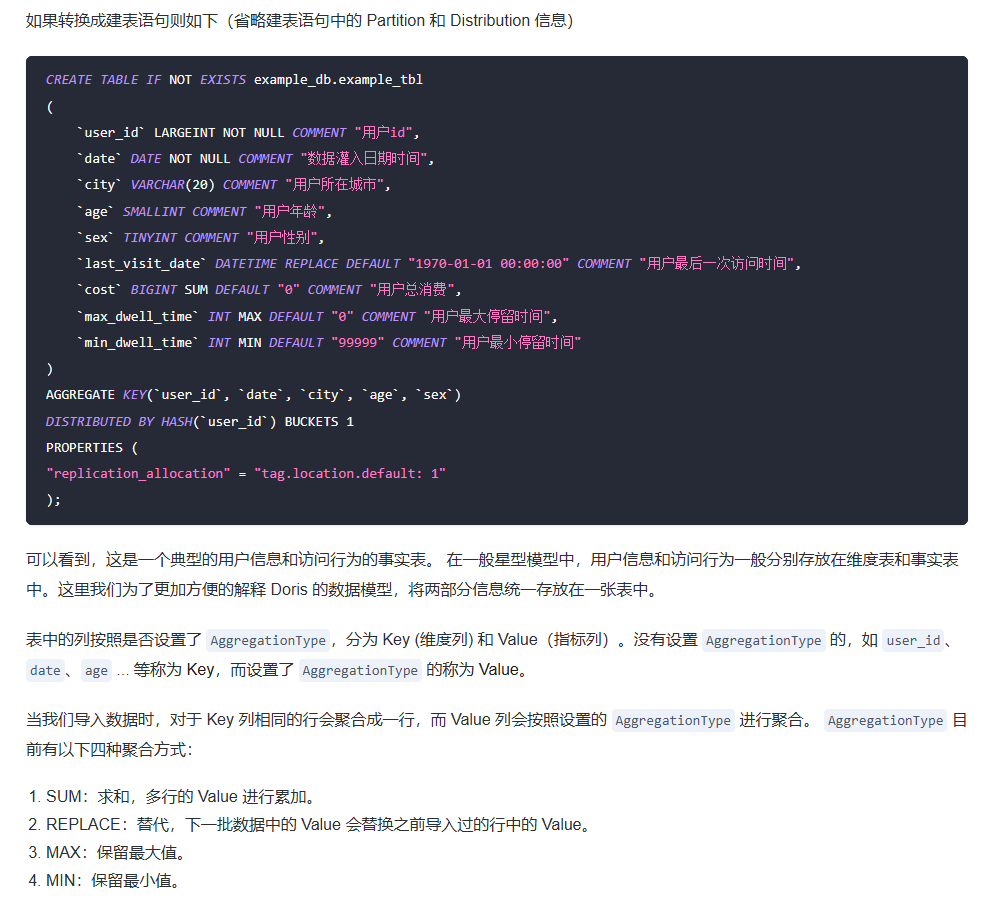
表结构
参考链接:数据模型 - Apache Doris
在Doris中,数据模型主要分为三种类型,分别是:
Aggregate(聚合)模型:
这种模型适用于需要对数据进行预聚合的场景,例如报表类查询。在这种模型中,表中的列被分为Key列(维度列)和Value列(指标列)。Key列相同的行会根据指定的聚合方式聚合成一行,而Value列会按照设置的聚合函数(如SUM、REPLACE、MAX、MIN等)进行聚合。
建表语句
CREATE TABLE example_db.aggregate_table ( `dt` DATE NOT NULL, `user_id` INT NOT NULL, `pv` BIGINT SUM DEFAULT 0 ) ENGINE=OLAP DUPLICATE KEY(`dt`, `user_id`) PARTITION BY RANGE(`dt`) ( PARTITION p2023 VALUES LESS THAN ('2024-01-01'), PARTITION p2024 VALUES LESS THAN ('2025-01-01') ) DISTRIBUTED BY HASH(`dt`) BUCKETS 16 PROPERTIES ( "replication_num" = "1" );在这个例子中,dt 和 user_id 是Key列,pv 是Value列,并且使用了SUM聚合函数。表按照dt进行范围分区,并且通过dt进行哈希分桶。
官网例子
Unique(唯一)模型:
这种模型适用于需要唯一主键约束的场景,可以保证主键的唯一性。在这种模型中,每一行都由键列中的值组合唯一标识,确保给定的键值集不存在重复行。这种模型无法利用物化等预聚合带来的查询优势,但对于需要保证数据唯一性的场景非常适用。
建表语句
CREATE TABLE example_db.unique_table ( `id` INT NOT NULL, `name` VARCHAR(64) NOT NULL, `create_time` DATETIME DEFAULT '1970-01-01 00:00:00' ) ENGINE=OLAP UNIQUE KEY(`id`) PARTITION BY RANGE(`create_time`) ( PARTITION p2023 VALUES LESS THAN ('2024-01-01'), PARTITION p2024 VALUES LESS THAN ('2025-01-01') ) DISTRIBUTED BY HASH(`id`) BUCKETS 16 PROPERTIES ( "replication_num" = "1" );在这个例子中,id 是唯一的主键,表按照create_time进行范围分区,并且通过id进行哈希分桶。
官网例子
Duplicate(重复)模型:
这种模型允许基于指定的键列存储重复行,适用于必须保留所有原始数据记录的场景。在这种模型中,只指定排序列,相同的Key行不会合并,适用于数据无需提前聚合的分析业务,如原始数据分析或仅追加新数据的日志或时序数据分析。
建表语句
CREATE TABLE example_db.duplicate_table ( `user_id` INT NOT NULL, `event_time` DATETIME DEFAULT '1970-01-01 00:00:00', `event_type` VARCHAR(64) DEFAULT '' ) ENGINE=OLAP DUPLICATE KEY(`user_id`) PARTITION BY RANGE(`event_time`) ( PARTITION p2023 VALUES LESS THAN ('2024-01-01'), PARTITION p2024 VALUES LESS THAN ('2025-01-01') ) DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 PROPERTIES ( "replication_num" = "1" );在这个例子中,user_id 是排序列,表允许有重复行,按照event_time进行范围分区,并且通过user_id进行哈希分桶。
官网例子

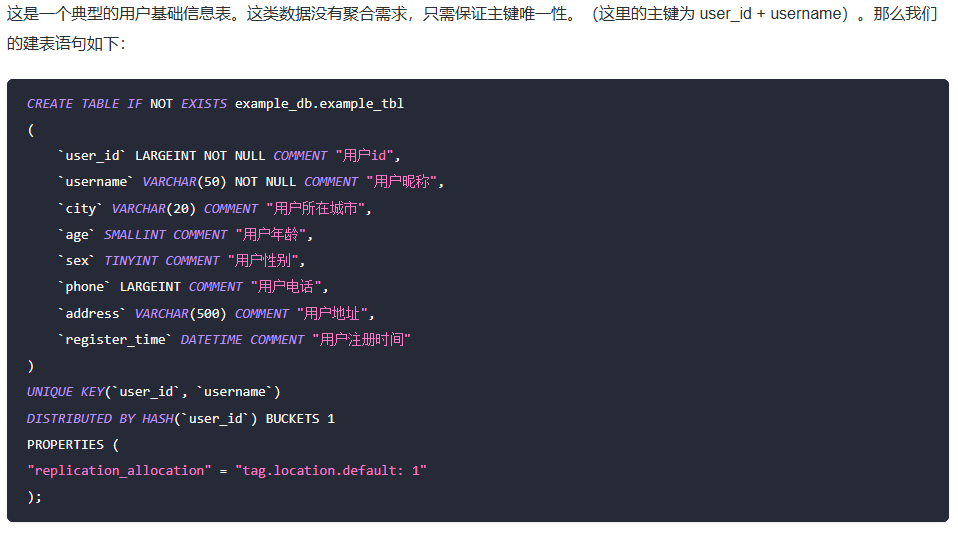
在 MySQL 中类似的表结构
Doris 的三种数据模型与 MySQL 中的数据类型有一定的相似性,但也有其特定的使用场景和优化。以下是 Doris 的数据模型与 MySQL 中相似类型的对比:
Aggregate(聚合)模型:
类似于 MySQL 中的汇总表(Summary Table)或物化视图(Materialized View)。在 MySQL 中,物化视图可以用来存储查询结果,特别是那些包含聚合函数(如 SUM、MAX、MIN)的结果。Doris 的 Aggregate 模型也是为了存储预聚合的结果,以优化读性能,这与物化视图的目的相似。
Unique(唯一)模型:
类似于 MySQL 中的具有唯一主键(PRIMARY KEY)或唯一索引(UNIQUE INDEX)的表。在 MySQL 中,唯一主键或唯一索引确保了表中不会有重复的行。Doris 的 Unique 模型也是为了保证数据的唯一性,不允许有重复的 Key 列组合。
Duplicate(重复)模型:
类似于 MySQL 中的普通表,没有唯一主键或唯一索引约束。在 MySQL 中,如果没有设置主键或唯一索引,表可以包含重复行。Doris 的 Duplicate 模型也是这样,它允许数据中有重复的 Key 列组合,主要用于存储原始数据,不做任何聚合。
需要注意的是,虽然 Doris 的这些模型在概念上与 MySQL 中的某些特性相似,但它们在实现和优化上是为了适应 Doris 作为一个 MPP(大规模并行处理)数据库的特点,特别是在处理大规模数据和高并发查询时的性能。Doris 的设计更侧重于 OLAP(在线分析处理)场景,而 MySQL 通常用于 OLTP(在线事务处理)场景。
OLTP 和 OLAP
OLAP(在线分析处理)和OLTP(在线事务处理)是数据库应用领域的两个重要概念,它们代表了数据库系统的两种不同应用场景和优化方向:
OLTP(在线事务处理)
定义:OLTP 是指数据库系统处理日常业务操作的能力,如转账、查询余额、下订单等。这些操作通常涉及对数据库的增删改查(CRUD)操作。
特点:
高并发:需要支持大量用户同时进行事务处理。
高可靠性和一致性:事务必须保持ACID属性(原子性、一致性、隔离性、持久性)。
响应时间快:对单个事务的响应时间要求高,通常在几毫秒到几秒内。
数据更新频繁:涉及大量的插入、更新和删除操作。
OLAP(在线分析处理)
定义:OLAP 是指数据库系统处理复杂查询和报告的能力,如数据挖掘、趋势分析、财务报告等。这些操作通常涉及对大量数据的聚合和分析。
特点:
数据量大:需要处理的数据量通常比OLTP大得多。
查询复杂:查询通常涉及多个表的连接、复杂的聚合函数和多维分析。
响应时间可接受较长:OLAP查询的响应时间可以较长,因为它们通常不涉及实时性要求。
数据更新不频繁:OLAP系统的数据通常以批量方式更新,而不是频繁的单个事务。
OLAP和OLTP的关系
互补性:OLTP 和 OLAP 通常在不同的系统中实现,以满足各自的性能要求。OLTP 系统优化了事务处理,而 OLAP 系统优化了数据分析。
数据流动:OLTP 系统中的数据最终会流向 OLAP 系统,以便进行分析和报告。这通常通过数据仓库(Data Warehouse)实现,数据从 OLTP 系统抽取、转换后加载到 OLAP 系统中。
技术差异:OLTP 数据库(如 MySQL、PostgreSQL)和 OLAP 数据库(如 Apache Doris、ClickHouse)在设计和技术上有很大差异,以适应不同的使用场景。
融合趋势:随着技术的发展,一些数据库系统开始尝试融合 OLTP 和 OLAP 的特性,提供混合负载(Hybrid Transactional/Analytical Processing, HTAP)的能力,即在同一数据库上同时处理事务和分析查询。
评论